Artificial Intelligence Nanodegree¶
Machine Translation Project¶
In this notebook, sections that end with '(IMPLEMENTATION)' in the header indicate that the following blocks of code will require additional functionality which you must provide. Please be sure to read the instructions carefully!
Introduction¶
In this notebook, you will build a deep neural network that functions as part of an end-to-end machine translation pipeline. Your completed pipeline will accept English text as input and return the French translation.
- Preprocess - You'll convert text to sequence of integers.
- Models Create models which accepts a sequence of integers as input and returns a probability distribution over possible translations. After learning about the basic types of neural networks that are often used for machine translation, you will engage in your own investigations, to design your own model!
- Prediction Run the model on English text.
%load_ext autoreload
%aimport helper, tests
%autoreload 1
import collections
import helper
import numpy as np
import project_tests as tests
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Model, Sequential
from keras.layers import GRU, Input, Dense, TimeDistributed, Activation, RepeatVector, Bidirectional, Dropout, LSTM
from keras.layers.embeddings import Embedding
from keras.optimizers import Adam
from keras.losses import sparse_categorical_crossentropy
Verify access to the GPU¶
The following test applies only if you expect to be using a GPU, e.g., while running in a Udacity Workspace or using an AWS instance with GPU support. Run the next cell, and verify that the device_type is "GPU".
- If the device is not GPU & you are running from a Udacity Workspace, then save your workspace with the icon at the top, then click "enable" at the bottom of the workspace.
- If the device is not GPU & you are running from an AWS instance, then refer to the cloud computing instructions in the classroom to verify your setup steps.
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
Dataset¶
We begin by investigating the dataset that will be used to train and evaluate your pipeline. The most common datasets used for machine translation are from WMT. However, that will take a long time to train a neural network on. We'll be using a dataset we created for this project that contains a small vocabulary. You'll be able to train your model in a reasonable time with this dataset.
Load Data¶
The data is located in data/small_vocab_en and data/small_vocab_fr. The small_vocab_en file contains English sentences with their French translations in the small_vocab_fr file. Load the English and French data from these files from running the cell below.
# Load English data
english_sentences = helper.load_data('data/small_vocab_en')
# Load French data
french_sentences = helper.load_data('data/small_vocab_fr')
print('Dataset Loaded')
Files¶
Each line in small_vocab_en contains an English sentence with the respective translation in each line of small_vocab_fr. View the first two lines from each file.
for sample_i in range(5):
print('English sample {}: {}'.format(sample_i + 1, english_sentences[sample_i]))
print('French sample {}: {}\n'.format(sample_i + 1, french_sentences[sample_i]))
From looking at the sentences, you can see they have been preprocessed already. The puncuations have been delimited using spaces. All the text have been converted to lowercase. This should save you some time, but the text requires more preprocessing.
Vocabulary¶
The complexity of the problem is determined by the complexity of the vocabulary. A more complex vocabulary is a more complex problem. Let's look at the complexity of the dataset we'll be working with.
english_words_counter = collections.Counter([word for sentence in english_sentences for word in sentence.split()])
french_words_counter = collections.Counter([word for sentence in french_sentences for word in sentence.split()])
print('{} English words.'.format(len([word for sentence in english_sentences for word in sentence.split()])))
print('{} unique English words.'.format(len(english_words_counter)))
print('10 Most common words in the English dataset:')
print('"' + '" "'.join(list(zip(*english_words_counter.most_common(10)))[0]) + '"')
print()
print('{} French words.'.format(len([word for sentence in french_sentences for word in sentence.split()])))
print('{} unique French words.'.format(len(french_words_counter)))
print('10 Most common words in the French dataset:')
print('"' + '" "'.join(list(zip(*french_words_counter.most_common(10)))[0]) + '"')
For comparison, Alice's Adventures in Wonderland contains 2,766 unique words of a total of 15,500 words.
Preprocess¶
For this project, you won't use text data as input to your model. Instead, you'll convert the text into sequences of integers using the following preprocess methods:
- Tokenize the words into ids
- Add padding to make all the sequences the same length.
Time to start preprocessing the data...
Tokenize (IMPLEMENTATION)¶
For a neural network to predict on text data, it first has to be turned into data it can understand. Text data like "dog" is a sequence of ASCII character encodings. Since a neural network is a series of multiplication and addition operations, the input data needs to be number(s).
We can turn each character into a number or each word into a number. These are called character and word ids, respectively. Character ids are used for character level models that generate text predictions for each character. A word level model uses word ids that generate text predictions for each word. Word level models tend to learn better, since they are lower in complexity, so we'll use those.
Turn each sentence into a sequence of words ids using Keras's Tokenizer function. Use this function to tokenize english_sentences and french_sentences in the cell below.
Running the cell will run tokenize on sample data and show output for debugging.
def tokenize(x):
"""
Tokenize x
:param x: List of sentences/strings to be tokenized
:return: Tuple of (tokenized x data, tokenizer used to tokenize x)
"""
# TODO: Implement
tokenizer = Tokenizer()
tokenizer.fit_on_texts(x)
return tokenizer.texts_to_sequences(x), tokenizer
tests.test_tokenize(tokenize)
# Tokenize Example output
text_sentences = [
'The quick brown fox jumps over the lazy dog .',
'By Jove , my quick study of lexicography won a prize .',
'This is a short sentence .']
text_tokenized, text_tokenizer = tokenize(text_sentences)
print(text_tokenizer.word_index)
print()
for sample_i, (sent, token_sent) in enumerate(zip(text_sentences, text_tokenized)):
print('Sequence {} in x'.format(sample_i + 1))
print(' Input: {}'.format(sent))
print(' Output: {}'.format(token_sent))
Padding (IMPLEMENTATION)¶
When batching the sequence of word ids together, each sequence needs to be the same length. Since sentences are dynamic in length, we can add padding to the end of the sequences to make them the same length.
Make sure all the English sequences have the same length and all the French sequences have the same length by adding padding to the end of each sequence using Keras's pad_sequences function.
def pad(x, length=None):
"""
Pad x
:param x: List of sequences.
:param length: Length to pad the sequence to. If None, use length of longest sequence in x.
:return: Padded numpy array of sequences
"""
# TODO: Implement
return pad_sequences(x, maxlen=length, padding='post')
tests.test_pad(pad)
# Pad Tokenized output
test_pad = pad(text_tokenized)
for sample_i, (token_sent, pad_sent) in enumerate(zip(text_tokenized, test_pad)):
print('Sequence {} in x'.format(sample_i + 1))
print(' Input: {}'.format(np.array(token_sent)))
print(' Output: {}'.format(pad_sent))
Preprocess Pipeline¶
Your focus for this project is to build neural network architecture, so we won't ask you to create a preprocess pipeline. Instead, we've provided you with the implementation of the preprocess function.
def preprocess(x, y):
"""
Preprocess x and y
:param x: Feature List of sentences
:param y: Label List of sentences
:return: Tuple of (Preprocessed x, Preprocessed y, x tokenizer, y tokenizer)
"""
preprocess_x, x_tk = tokenize(x)
preprocess_y, y_tk = tokenize(y)
preprocess_x = pad(preprocess_x)
preprocess_y = pad(preprocess_y)
# Keras's sparse_categorical_crossentropy function requires the labels to be in 3 dimensions
preprocess_y = preprocess_y.reshape(*preprocess_y.shape, 1)
return preprocess_x, preprocess_y, x_tk, y_tk
preproc_english_sentences, preproc_french_sentences, english_tokenizer, french_tokenizer =\
preprocess(english_sentences, french_sentences)
max_english_sequence_length = preproc_english_sentences.shape[1]
max_french_sequence_length = preproc_french_sentences.shape[1]
english_vocab_size = len(english_tokenizer.word_index)
french_vocab_size = len(french_tokenizer.word_index)
print('Data Preprocessed')
print("Max English sentence length:", max_english_sequence_length)
print("Max French sentence length:", max_french_sequence_length)
print("English vocabulary size:", english_vocab_size)
print("French vocabulary size:", french_vocab_size)
Models¶
In this section, you will experiment with various neural network architectures. You will begin by training four relatively simple architectures.
- Model 1 is a simple RNN
- Model 2 is a RNN with Embedding
- Model 3 is a Bidirectional RNN
- Model 4 is an optional Encoder-Decoder RNN
After experimenting with the four simple architectures, you will construct a deeper architecture that is designed to outperform all four models.
Ids Back to Text¶
The neural network will be translating the input to words ids, which isn't the final form we want. We want the French translation. The function logits_to_text will bridge the gab between the logits from the neural network to the French translation. You'll be using this function to better understand the output of the neural network.
def logits_to_text(logits, tokenizer):
"""
Turn logits from a neural network into text using the tokenizer
:param logits: Logits from a neural network
:param tokenizer: Keras Tokenizer fit on the labels
:return: String that represents the text of the logits
"""
index_to_words = {id: word for word, id in tokenizer.word_index.items()}
index_to_words[0] = '<PAD>'
return ' '.join([index_to_words[prediction] for prediction in np.argmax(logits, 1)])
print('`logits_to_text` function loaded.')
Model 1: RNN (IMPLEMENTATION)¶
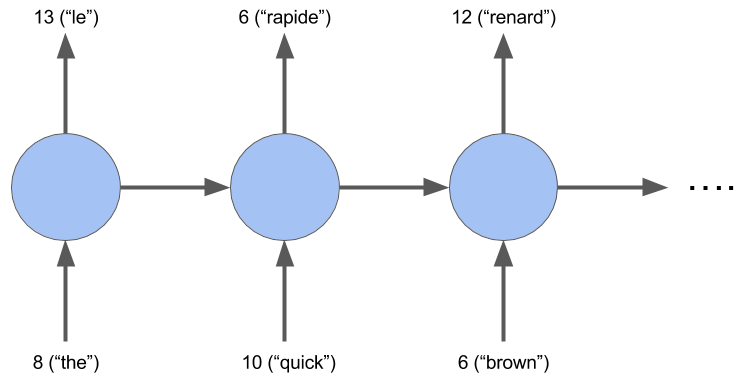 A basic RNN model is a good baseline for sequence data. In this model, you'll build a RNN that translates English to French.
A basic RNN model is a good baseline for sequence data. In this model, you'll build a RNN that translates English to French.
def simple_model(input_shape, output_sequence_length, english_vocab_size, french_vocab_size):
"""
Build and train a basic RNN on x and y
:param input_shape: Tuple of input shape
:param output_sequence_length: Length of output sequence
:param english_vocab_size: Number of unique English words in the dataset
:param french_vocab_size: Number of unique French words in the dataset
:return: Keras model built, but not trained
"""
# Hyperparameters
learning_rate = 0.005
# TODO: Build the layers
model = Sequential()
model.add(GRU(256, input_shape=input_shape[1:], return_sequences=True))
model.add(TimeDistributed(Dense(1024, activation='relu')))
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(french_vocab_size, activation='softmax')))
# Compile model
model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(learning_rate),
metrics=['accuracy'])
return model
tests.test_simple_model(simple_model)
# Reshaping the input to work with a basic RNN
tmp_x = pad(preproc_english_sentences, max_french_sequence_length)
tmp_x = tmp_x.reshape((-1, preproc_french_sentences.shape[-2], 1))
# Train the neural network
simple_rnn_model = simple_model(
tmp_x.shape,
max_french_sequence_length,
english_vocab_size,
french_vocab_size)
print(simple_rnn_model.summary())
simple_rnn_model.fit(tmp_x, preproc_french_sentences, batch_size=1024, epochs=10, validation_split=0.2)
# Print prediction(s)
print(logits_to_text(simple_rnn_model.predict(tmp_x[:1])[0], french_tokenizer))
# Print prediction(s)
print("Prediction:")
print(logits_to_text(simple_rnn_model.predict(tmp_x[:1])[0], french_tokenizer))
print("\nCorrect Translation:")
print(french_sentences[:1])
print("\nOriginal text:")
print(english_sentences[:1])
Model 2: Embedding (IMPLEMENTATION)¶
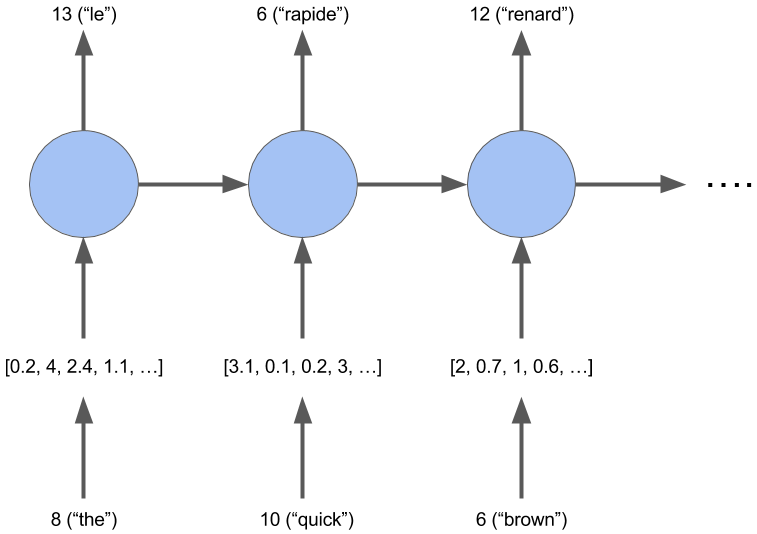 You've turned the words into ids, but there's a better representation of a word. This is called word embeddings. An embedding is a vector representation of the word that is close to similar words in n-dimensional space, where the n represents the size of the embedding vectors.
You've turned the words into ids, but there's a better representation of a word. This is called word embeddings. An embedding is a vector representation of the word that is close to similar words in n-dimensional space, where the n represents the size of the embedding vectors.
In this model, you'll create a RNN model using embedding.
def embed_model(input_shape, output_sequence_length, english_vocab_size, french_vocab_size):
"""
Build and train a RNN model using word embedding on x and y
:param input_shape: Tuple of input shape
:param output_sequence_length: Length of output sequence
:param english_vocab_size: Number of unique English words in the dataset
:param french_vocab_size: Number of unique French words in the dataset
:return: Keras model built, but not trained
"""
# TODO: Implement
# Hyperparameters
learning_rate = 0.005
# TODO: Build the layers
model = Sequential()
model.add(Embedding(english_vocab_size, 256, input_length=input_shape[1], input_shape=input_shape[1:]))
model.add(GRU(256, return_sequences=True))
model.add(TimeDistributed(Dense(1024, activation='relu')))
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(french_vocab_size, activation='softmax')))
# Compile model
model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(learning_rate),
metrics=['accuracy'])
return model
tests.test_embed_model(embed_model)
# TODO: Reshape the input
tmp_x = pad(preproc_english_sentences, preproc_french_sentences.shape[1])
tmp_x = tmp_x.reshape((-1, preproc_french_sentences.shape[-2]))
# TODO: Train the neural network
embed_rnn_model = embed_model(
tmp_x.shape,
preproc_french_sentences.shape[1],
len(english_tokenizer.word_index)+1,
len(french_tokenizer.word_index)+1)
embed_rnn_model.summary()
embed_rnn_model.fit(tmp_x, preproc_french_sentences, batch_size=1024, epochs=10, validation_split=0.2)
# TODO: Print prediction(s)
print(logits_to_text(embed_rnn_model.predict(tmp_x[:1])[0], french_tokenizer))
# Print prediction(s)
print("Prediction:")
print(logits_to_text(embed_rnn_model.predict(tmp_x[:1])[0], french_tokenizer))
print("\nCorrect Translation:")
print(french_sentences[:1])
print("\nOriginal text:")
print(english_sentences[:1])
Model 3: Bidirectional RNNs (IMPLEMENTATION)¶
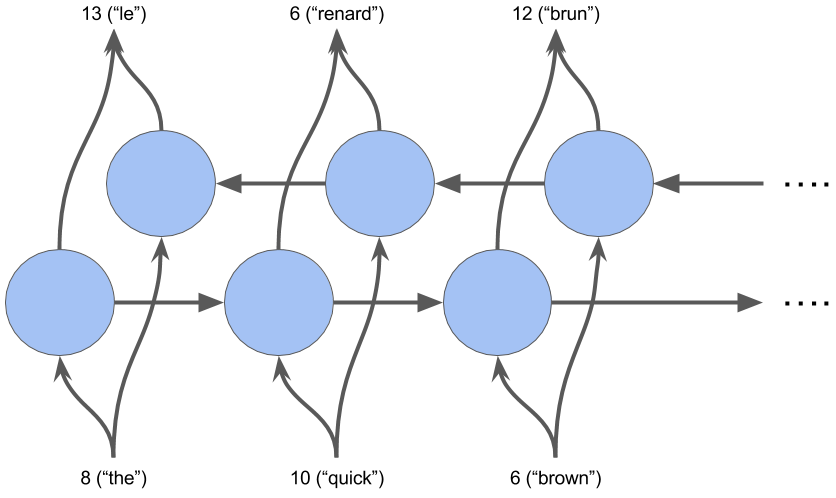 One restriction of a RNN is that it can't see the future input, only the past. This is where bidirectional recurrent neural networks come in. They are able to see the future data.
One restriction of a RNN is that it can't see the future input, only the past. This is where bidirectional recurrent neural networks come in. They are able to see the future data.
def bd_model(input_shape, output_sequence_length, english_vocab_size, french_vocab_size):
"""
Build and train a bidirectional RNN model on x and y
:param input_shape: Tuple of input shape
:param output_sequence_length: Length of output sequence
:param english_vocab_size: Number of unique English words in the dataset
:param french_vocab_size: Number of unique French words in the dataset
:return: Keras model built, but not trained
"""
# TODO: Implement
# Hyperparameters
learning_rate = 0.003
# TODO: Build the layers
model = Sequential()
model.add(Bidirectional(GRU(128, return_sequences=True), input_shape=input_shape[1:]))
model.add(TimeDistributed(Dense(1024, activation='relu')))
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(french_vocab_size, activation='softmax')))
# Compile model
model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(learning_rate),
metrics=['accuracy'])
return model
tests.test_bd_model(bd_model)
# TODO: Reshape the input
tmp_x = pad(preproc_english_sentences, preproc_french_sentences.shape[1])
tmp_x = tmp_x.reshape((-1, preproc_french_sentences.shape[-2]))
# TODO: Train and Print prediction(s)
embed_rnn_model = embed_model(
tmp_x.shape,
preproc_french_sentences.shape[1],
len(english_tokenizer.word_index)+1,
len(french_tokenizer.word_index)+1)
embed_rnn_model.summary()
embed_rnn_model.fit(tmp_x, preproc_french_sentences, batch_size=1024, epochs=10, validation_split=0.2)
print(logits_to_text(embed_rnn_model.predict(tmp_x[:1])[0], french_tokenizer))
# Print prediction(s)
print("Prediction:")
print(logits_to_text(embed_rnn_model.predict(tmp_x[:1])[0], french_tokenizer))
print("\nCorrect Translation:")
print(french_sentences[:1])
print("\nOriginal text:")
print(english_sentences[:1])
Model 4: Encoder-Decoder (OPTIONAL)¶
Time to look at encoder-decoder models. This model is made up of an encoder and decoder. The encoder creates a matrix representation of the sentence. The decoder takes this matrix as input and predicts the translation as output.
Create an encoder-decoder model in the cell below.
def encdec_model(input_shape, output_sequence_length, english_vocab_size, french_vocab_size):
"""
Build and train an encoder-decoder model on x and y
:param input_shape: Tuple of input shape
:param output_sequence_length: Length of output sequence
:param english_vocab_size: Number of unique English words in the dataset
:param french_vocab_size: Number of unique French words in the dataset
:return: Keras model built, but not trained
"""
# OPTIONAL: Implement
# Hyperparameters
learning_rate = 0.001
# Build the layers
model = Sequential()
# Encoder
model.add(GRU(256, input_shape=input_shape[1:], go_backwards=True))
model.add(RepeatVector(output_sequence_length))
# Decoder
model.add(GRU(256, return_sequences=True))
model.add(TimeDistributed(Dense(1024, activation='relu')))
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(french_vocab_size, activation='softmax')))
# Compile model
model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(learning_rate),
metrics=['accuracy'])
return model
tests.test_encdec_model(encdec_model)
# Reshape the input
tmp_x = pad(preproc_english_sentences, preproc_french_sentences.shape[1])
tmp_x = tmp_x.reshape((-1, preproc_french_sentences.shape[-2], 1))
# Train and Print prediction(s)
encdec_rnn_model = encdec_model(
tmp_x.shape,
preproc_french_sentences.shape[1],
len(english_tokenizer.word_index)+1,
len(french_tokenizer.word_index)+1)
encdec_rnn_model.summary()
encdec_rnn_model.fit(tmp_x, preproc_french_sentences, batch_size=1024, epochs=10, validation_split=0.2)
# Print prediction(s)
print("Prediction:")
print(logits_to_text(encdec_rnn_model.predict(tmp_x[:1])[0], french_tokenizer))
print("\nCorrect Translation:")
print(french_sentences[:1])
print("\nOriginal text:")
print(english_sentences[:1])
Model 5: Custom (IMPLEMENTATION)¶
Use everything you learned from the previous models to create a model that incorporates embedding and a bidirectional rnn into one model.
def model_final(input_shape, output_sequence_length, english_vocab_size, french_vocab_size):
"""
Build and train a model that incorporates embedding, encoder-decoder, and bidirectional RNN on x and y
:param input_shape: Tuple of input shape
:param output_sequence_length: Length of output sequence
:param english_vocab_size: Number of unique English words in the dataset
:param french_vocab_size: Number of unique French words in the dataset
:return: Keras model built, but not trained
"""
# TODO: Implement
# Hyperparameters
learning_rate = 0.003
# Build the layers
model = Sequential()
# Embedding
model.add(Embedding(english_vocab_size, 128, input_length=input_shape[1],
input_shape=input_shape[1:]))
# Encoder
model.add(Bidirectional(GRU(128)))
model.add(RepeatVector(output_sequence_length))
# Decoder
model.add(Bidirectional(GRU(128, return_sequences=True)))
model.add(TimeDistributed(Dense(512, activation='relu')))
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(french_vocab_size, activation='softmax')))
model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(learning_rate),
metrics=['accuracy'])
return model
tests.test_model_final(model_final)
print('Final Model Loaded')
Prediction (IMPLEMENTATION)¶
def final_predictions(x, y, x_tk, y_tk):
"""
Gets predictions using the final model
:param x: Preprocessed English data
:param y: Preprocessed French data
:param x_tk: English tokenizer
:param y_tk: French tokenizer
"""
# TODO: Train neural network using model_final
model = model_final(x.shape,y.shape[1],
len(x_tk.word_index)+1,
len(y_tk.word_index)+1)
model.summary()
model.fit(x, y, batch_size=1024, epochs=25, validation_split=0.2)
## DON'T EDIT ANYTHING BELOW THIS LINE
y_id_to_word = {value: key for key, value in y_tk.word_index.items()}
y_id_to_word[0] = '<PAD>'
sentence = 'he saw a old yellow truck'
sentence = [x_tk.word_index[word] for word in sentence.split()]
sentence = pad_sequences([sentence], maxlen=x.shape[-1], padding='post')
sentences = np.array([sentence[0], x[0]])
predictions = model.predict(sentences, len(sentences))
print('Sample 1:')
print(' '.join([y_id_to_word[np.argmax(x)] for x in predictions[0]]))
print('Il a vu un vieux camion jaune')
print('Sample 2:')
print(' '.join([y_id_to_word[np.argmax(x)] for x in predictions[1]]))
print(' '.join([y_id_to_word[np.max(x)] for x in y[0]]))
final_predictions(preproc_english_sentences, preproc_french_sentences, english_tokenizer, french_tokenizer)
Submission¶
When you're ready to submit, complete the following steps:
- Review the rubric to ensure your submission meets all requirements to pass
Generate an HTML version of this notebook
- Run the next cell to attempt automatic generation (this is the recommended method in Workspaces)
- Navigate to FILE -> Download as -> HTML (.html)
- Manually generate a copy using
nbconvertfrom your shell terminal$ pip install nbconvert $ python -m nbconvert machine_translation.ipynb
Submit the project
If you are in a Workspace, simply click the "Submit Project" button (bottom towards the right)
Otherwise, add the following files into a zip archive and submit them
helper.pymachine_translation.ipynbmachine_translation.html- You can export the notebook by navigating to File -> Download as -> HTML (.html).
Generate the html¶
Save your notebook before running the next cell to generate the HTML output. Then submit your project.
# Save before you run this cell!
!!jupyter nbconvert *.ipynb
Optional Enhancements¶
This project focuses on learning various network architectures for machine translation, but we don't evaluate the models according to best practices by splitting the data into separate test & training sets -- so the model accuracy is overstated. Use the sklearn.model_selection.train_test_split() function to create separate training & test datasets, then retrain each of the models using only the training set and evaluate the prediction accuracy using the hold out test set. Does the "best" model change?